Apache Spark is renowned for its speed and efficiency in handling large-scale data processing. However, optimizing Spark to achieve maximum performance requires a precise understanding of its inner workings. This blog post will guide you through establishing a Spark Performance Lab with essential tools and techniques aimed at enhancing Spark performance through detailed metrics analysis.
Why a Spark Performance Lab
The purpose of a Spark Performance Lab isn't just to measure the elapsed time of your Spark jobs but to understand the underlying performance metrics deeply. By using these metrics, you can create models that explain what's happening within Spark's execution and identify areas for improvement. Here are some key reasons to set up a Spark Performance Lab:
Hands-on learning and testing: A controlled lab setting allows for safer experimentation with Spark configurations and tuning and also experimenting and understanding the monitoring tools and Spark-generated metrics.
Load and scale: Our lab uses a workload generator, running TPCDS queries. This is a well-known set of complex queries that is representative of OLAP workloads, and that can easily be scaled up for testing from GBs to 100s of TBs.
Improving your toolkit: Having a toolbox is invaluable, however you need to practice and understand their output in a sandbox environment before moving to production.
Get value from the Spark metric system: Instead of focusing solely on how long a job takes, use detailed metrics to understand the performance and spot inefficiencies.
Tools and Components
In our Spark Performance Lab, several key tools and components form the backbone of our testing and monitoring environment:
Workload generator:
We use a custom tool, TPCDS-PySpark, to generate a consistent set of queries (TPCDS benchmark), creating a reliable testing framework.
Spark instrumentation:
Spark’s built-in Web UIfor initial metrics and job visualization.
Custom tools:
SparkMeasure: Use this for detailed performance metrics collection.
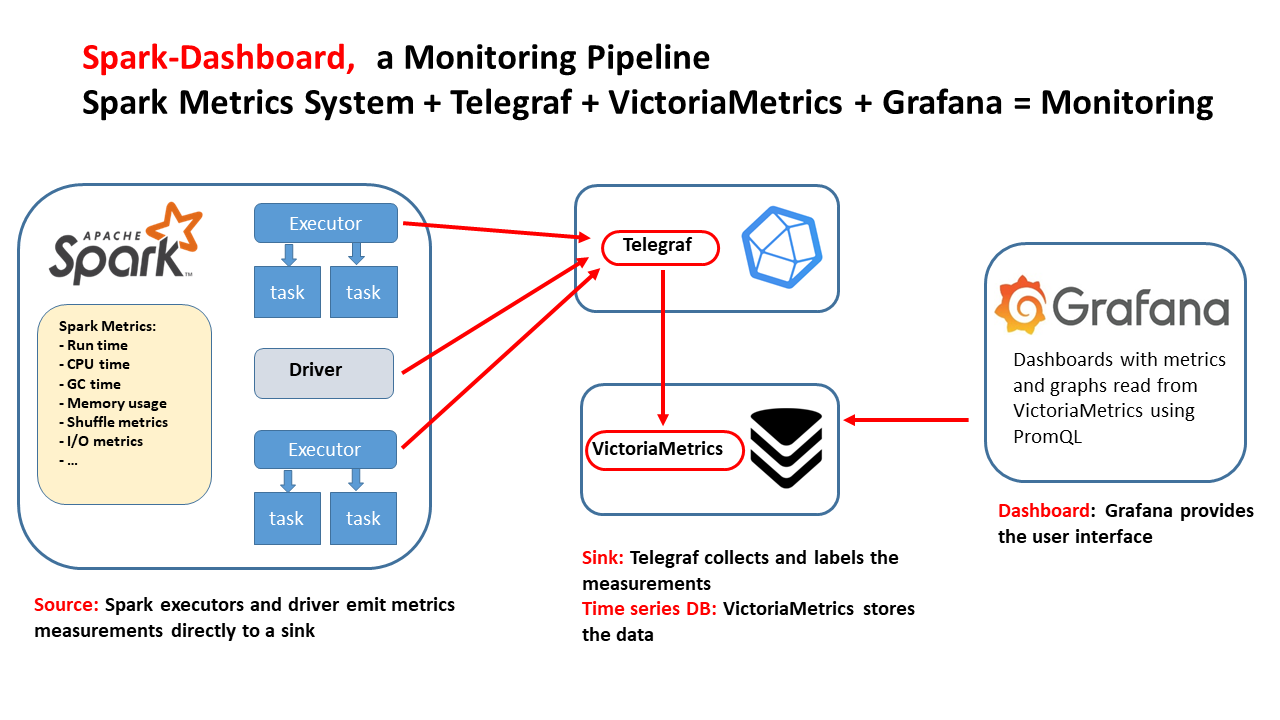
Spark-Dashboard: Use this to monitor Spark jobs and visualize key performance metrics.
Additional tools for Performance Measurement include:
These quick demos and tutorials will show you how to use the tools in this Spark Performance Lab. You can follow along and get the same results on your own, which will help you start learning and exploring.
Figure 1: The graph illustrates the dynamic task allocation in a Spark application during a TPCDS 10TB benchmark on a YARN cluster with 256 cores. It showcases the variability in the number of active tasks over time, highlighting instances of execution "long tails" and straggler tasks, as seen in the periodic spikes and troughs.
How to Make the Best of Spark Metrics System
Understanding and utilizing Spark's metrics system is crucial for optimization:
Importance of Metrics: Metrics provide insights beyond simple timing, revealing details about task execution, resource utilization, and bottlenecks.
Execution Time is Not Enough: Measuring the execution time of a job (how long it took to run it), is useful, but it doesn’t show the whole picture. Say the job ran in 10 seconds. It's crucial to understand why it took 10 seconds instead of 100 seconds or just 1 second. What was slowing things down? Was it the CPU, data input/output, or something else, like data shuffling? This helps us identify the root causes of performance issues.
Key Metrics to Collect:
Executor Run Time: Total time executors spend processing tasks.
Executor CPU Time: Direct CPU time consumed by tasks.
JVM GC Time: Time spent in garbage collection, affecting performance.
Shuffle and I/O Metrics: Critical for understanding data movement and disk interactions.
Memory Metrics: Key for performance and troubleshooting Out Of Memory errors.
Metrics Analysis, what to look for:
Look for bottlenecks: are there resources that are the bottleneck? Are the jobs running mostly on CPU or waiting for I/O or spending a lot of time on Garbage Collection?
USE method: Utilization Saturation and Errors (USE) Method is a methodology for analyzing the performance of any system.
The tools described here can help you to measure and understand Utilization and Saturation.
Can your job use a significant fraction of the available CPU cores?
Examine the measurement of the actual number of active tasks vs. time.
Figure 1 shows the number of active tasks measured while running TPCDS 10TB on a YARN cluster, with 256 cores allocated. The graph shows spikes and troughs.
Understand the root causes of the troughs using metrics and monitoring data. The reasons can be many: resource allocation, partition skew, straggler tasks, stage boundaries, etc.
Which tool should I use?
Start with using the Spark Web UI
Instrument your jobs with sparkMesure. This is recommended early in the application development, testing, and for Continuous Integration (CI) pipelines.
Observe your Spark application execution profile with Spark-Dashboard.
Use available tools with OS metrics too. See also Spark-Dashboard extended instrumentation: it collects and visualizes OS metrics (from cgroup statistics) like network stats, etc
For those interested in delving deeper into Spark instrumentation and metrics, the Spark documentation offers a comprehensive guide.
SparkMeasure: This tool captures metrics directly from Spark’s instrumentation via the Listener Bus. For a detailed understanding of how it operates, refer to the SparkMeasure architecture. It specifically gathers data from Spark's Task Metrics System, which you can explore further here.
Figure 2: This technical drawing outlines the integrated monitoring pipeline for Apache Spark implemented by Spark-Dashboard using open-source components. The flow of the diagram illustrates the Spark metrics source and the components used to store and visualize the metrics.
Lessons Learned and Conclusions
From setting up and running a Spark Performance Lab, here are some key takeaways:
Collect, analyze and visualize metrics: Go beyond just measuring jobs' execution times to troubleshoot and fine-tune Spark performance effectively.
Use the Right Tools: Familiarize yourself with tools for performance measurement and monitoring.
Start Small, Scale Up: Begin with smaller datasets and configurations, then gradually scale to test larger, more complex scenarios.
Tuning is an Iterative Process: Experiment with different configurations, parallelism levels, and data partitioning strategies to find the best setup for your workload.
Establishing a Spark Performance Lab is a fundamental step for any data engineer aiming to master Spark's performance aspects. By integrating tools like Web UI, TPCDS_PySpark, sparkMeasure, and Spark-Dashboard, developers and data engineers can gain unprecedented insights into Spark operations and optimizations.
Explore this lab setup to turn theory into expertise in managing and optimizing Apache Spark. Learn by doing and experimentation!
Acknowledgements: A special acknowledgment goes out to the teams behind the CERN data
analytics, monitoring, and web notebook services, as well as the
dedicated members of the ATLAS database group.
Resources
To get started with the tools mentioned in this blog:
In the ever-evolving landscape of big data, Apache Spark and Apache Parquet continue to introduce game-changing features. Their latest updates have brought forward significant enhancements, including column indexes, bloom filters. This blog post delves into these new features, exploring their applications and benefits. This post is based on the extended notes at:
This is not an introductory article, however here is a quick recap of why you may want to spend time learning more about Apache Parquet and Spark. Parquet is a columnar storage file format optimized for use with data processing frameworks like Apache Spark. It offers efficient data compression and encoding schemes.
Parquet is a columnar format enabling efficient data storage and retrieval
It supports compression and encoding
Optimizations in Spark for Parquet include:
Vectorized Parquet reader
Filter push down capabilities
Enhanced support for partitioning and handling large files
Another key aspect of Parquet with Spark that are important to know for the following is:
Row Group Organization: Parquet files consist of one or more 'row groups,' typically sized around 128 MB, although this is adjustable.
Parallel Processing Capabilities: Both Spark and other engines can process Parquet data in parallel, leveraging the row group level or the file level for enhanced efficiency.
Row Group Statistics: Each row group holds vital statistics like minimum and maximum values, counts, and the number of nulls. These stats enable the 'skip data' feature when filters are applied, essentially serving as a zone map to optimize query performance.
ORC: For a comparison of Apache Parquet with another popular data format, Apache ORC, refer to Parquet-ORC Comparison.
Understanding Column Indexes and Bloom Filters in Parquet
Column Indexes: Enhancing Query Efficiency
Column indexes, introduced in Parquet 1.11 and utilized in Spark 3.2.0 and higher, offer a fine-grained approach to data filtering. These indexes store min and max values at the Parquet page level, allowing Spark to efficiently execute filter predicates at a much finer granularity than the default 128 MB row group size. Particularly effective for sorted data, column indexes can drastically reduce the data read from disk, improving query performance.
Bloom Filters: A Leap in Filter Operations
Parquet 1.12 (utilized by Spark 3.2.0 and higher) introduced Bloom filters, a probabilistic data structure that efficiently determines whether an element is in a set. They are particularly useful for columns with high cardinality and scenarios where filter operations are based on values likely to be absent from the dataset. Using bloom filters can lead to significant improvements in read performance.
Example: Spark using Parquet column indexes
Test dataset and preparation
The Parquet test file used below parquet112file_sorted is extracted from the TPCDS benchmark table web_sales
the table (parquet file) contains data sorted on the column ws_sold_time_sk
it's important that the data is sorted, this groups together values in the filter column "ws_sold_time_sk", if the values are scattered the column index min-max statistics will have a wide range and will not be able to help with skipping data
the sorted dataset has been created using spark.read.parquet("path + "web_sales_piece.parquet").sort("ws_sold_time_sk").coalesce(1).write.parquet(path + "web_sales_piece_sorted_ws_sold_time_sk.parquet")
Download the test data:
Retrieve the test data using wget, a web browser, or any method of your choosing
Fast (reads only 20k rows): Spark will read the Parquet using a filter and makes use of column and offset indexes:
bin/spark-shell
val path = "./"
val df = spark.read.parquet(path + "web_sales_piece_sorted_ws_sold_time_sk.parquet")
// Read the file using a filter, this will use column and offset indexes
val q1 = df.filter("ws_sold_time_sk=28801")
val plan = q1.queryExecution.executedPlan
q1.collect
// Use Spark metrics to see how many rows were processed
// This is also available for the WebUI in graphical form
val metrics = plan.collectLeaves().head.metrics
metrics("numOutputRows").value
res: Long = 20000
The result shows that only 20000 rows were processed, this corresponds to processing just a few pages, as opposed to reading and processing the entire file. This is made possible by the use of the min-max value statistics in the column index for column ws_sold_time_sk. Column indexes are created by default in Spark version 3.2.x and higher.
Slow (reads 2M rows): Same as above, but this time we disable the use of column indexes. Note this is also what happens if you use Spark versions prior to Spark 3.2.0 (notably Spark 2.x) to read the file.
bin/spark-shell
val path = "./"
// disable the use of column indexes for testing purposes
val df = spark.read.option("parquet.filter.columnindex.enabled","false").parquet(path + "web_sales_piece_sorted_ws_sold_time_sk.parquet")
val q1 = df.filter("ws_sold_time_sk=28801")
val plan = q1.queryExecution.executedPlan
q1.collect
// Use Spark metrics to see how many rows were processed
val metrics = plan.collectLeaves().head.metrics
metrics("numOutputRows").value
res: Long = 2088626
The result is that all the rows in the row group (2088626 rows in the example) were read as Spark could not push the filter down to the Parquet page level. This example runs more slowly than the example below and in general performs more work (uses more CPU cycles and reads more data from the filesystem).
Diagnostics and Internals of Column and Offset Indexes
Column indexes in Parquet are key structures designed to optimize filter performance during data reads. They are particularly effective for managing and querying large datasets.
Key Aspects of Column Indexes:
Purpose and Functionality: Column indexes offer statistical data (minimum and maximum values) at the page level, facilitating efficient filter evaluation and optimization.
Default Activation: By default, column indexes are enabled to ensure optimal query performance.
Granularity Insights: While column indexes provide page-level statistics, similar statistics are also available at the row group level. Typically, a row group is approximately 128MB, contrasting with pages usually around 1MB.
Customization Options: Both rowgroup and page sizes are configurable, offering flexibility to tailor data organization. For further details, see Parquet Configuration Options.
Complementary Role of Offset Indexes:
Association with Column Indexes: Offset indexes work in tandem with column indexes and are stored in the file's footer in Parquet versions 1.11 and above.
Scanning Efficiency: A key benefit of these indexes is their role in data scanning. When filters are not applied in Parquet file scans, the footers with column index data can be efficiently skipped, enhancing the scanning process.
Additional Resources:
For an in-depth explanation of column and offset indexes in Parquet, consider reading this detailed description.
The integration of column and offset indexes significantly improves Parquet's capability in efficiently handling large-scale data, especially in scenarios involving filtered reads. Proper understanding and utilization of these indexes can lead to marked performance improvements in data processing workflows.
Tools to drill down on column index metadata in Parquet files
parquet-cli
example: hadoop jar target/parquet-cli-1.13.1-runtime.jar org.apache.parquet.cli.Main column-index -c ws_sold_time_sk <path>/my_parquetfile
// customize with the file path and name
val fullPathUri = java.net.URI.create("<path>/myParquetFile")
// crate a Hadoop input file and opens it with ParquetFileReader
val in = org.apache.parquet.hadoop.util.HadoopInputFile.fromPath(new org.apache.hadoop.fs.Path(fullPathUri), spark.sessionState.newHadoopConf())
val pf = org.apache.parquet.hadoop.ParquetFileReader.open(in)
// Get the Parquet file version
pf.getFooter.getFileMetaData.getCreatedBy
// columns index
val columnIndex = pf.readColumnIndex(columns.get(0))
columnIndex.toString.foreach(print)
// offset index
pf.readOffsetIndex(columns.get(0))
print(pf.readOffsetIndex(columns.get(0)))
With the release of Parquet 1.12, there's now the capability to generate and store Bloom filters within the file footer's metadata. This addition significantly enhances query performance for specific filtering operations. Bloom filters are especially advantageous in the following scenarios:
High Cardinality Columns: They effectively address the limitations inherent in using Parquet dictionaries for columns with a vast range of unique values.
Absent Value Filtering: Bloom filters are highly efficient for queries that filter based on values likely to be missing from the table or DataFrame. This efficiency stems from the characteristic of Bloom filters where false positives (erroneously concluding that a non-existent value is present) are possible, but false negatives (failing to identify an existing value) do not occur.
Important configurations for writing bloom filters in Parquet files are:
.option("parquet.bloom.filter.enabled","true") // write bloom filters for all columns, default is false
.option("parquet.bloom.filter.enabled#column_name", "true") // write bloom filter for the given column
.option("parquet.bloom.filter.expected.ndv#column_name", num_values) // tuning for bloom filters, ndv = number of distinct values
.option("parquet.bloom.filter.max.bytes", 1024*1024) // The maximum number of bytes for a bloom filter bitset, default 1 MB
Write Parquet files with Bloom filters
This is an example of how to read a Parquet file without bloom filter (for example because it had been created with an older version of Spark/Parquet) and add the bloom filter, with additional tuning of the bloom filter parameters for one of the columns:
val df = spark.read.parquet("<path>/web_sales")
df.coalesce(1).write.option("parquet.bloom.filter.enabled","true").option("parquet.bloom.filter.expected.ndv#ws_sold_time_sk", 25000).parquet("<myfilepath")
Example: Checking I/O Performance in Parquet: With and Without Bloom Filters
Understanding the impact of using bloom filters on I/O performance during Parquet file reads can be important for optimizing data processing. This example outlines the steps to compare I/O performance when reading Parquet files, both with and without the utilization of bloom filters.
This example uses Parquet bloom filters to improve Spark read performance
1. Prepare the test table
bin/spark-shell
val numDistinctVals=1e6.toInt
val df=sql(s"select id, int(random()*100*$numDistinctVals) randomval from range($numDistinctVals)")
val path = "./"
// Write the test DataFrame into a Parquet file with a Bloom filter
df.coalesce(1).write.mode("overwrite").option("parquet.bloom.filter.enabled","true").option("parquet.bloom.filter.enabled#randomval", "true").option("parquet.bloom.filter.expected.ndv#randomval", numDistinctVals).parquet(path + "spark320_test_bloomfilter")
// Write the same DataFrame in Parquet, but this time without Bloom filters
df.coalesce(1).write.mode("overwrite").option("parquet.bloom.filter.enabled","false").parquet(path + "spark320_test_bloomfilter_nofilter")
// use the OS (ls -l) to compare the size of the files with bloom filter and without
// in my test (Spark 3.5.0, Parquet 1.13.1) it was 10107275 with bloom filter and 8010077 without
:quit
2. Read data using the Bloom filter, for improved performance
bin/spark-shell
val path = "./"
val df =spark.read.option("parquet.filter.bloom.enabled","true").parquet(path + "spark320_test_bloomfilter")
val q1 = df.filter("randomval=1000000") // filter for a value that is not in the file
q1.collect
// print I/O metrics
org.apache.hadoop.fs.FileSystem.printStatistics()
// Output
FileSystem org.apache.hadoop.fs.RawLocalFileSystem: 1091611 bytes read, ...
:quit
3. Read disabling the Bloom filter (this will read more data from the filesystem and have worse performance)
bin/spark-shell
val path = "./"
val df =spark.read.option("parquet.filter.bloom.enabled","false").parquet(path + "spark320_test_bloomfilter")
val q1 = df.filter("randomval=1000000") // filter for a value that is not in the file
q1.collect
// print I/O metrics
org.apache.hadoop.fs.FileSystem.printStatistics()
// Output
FileSystem org.apache.hadoop.fs.RawLocalFileSystem: 8299656 bytes read, ...
Reading Parquet Bloom Filter Metadata with Apache Parquet Java API
To extract metadata about the bloom filter from a Parquet file using the Apache Parquet Java API in spark-shell, follow these steps:
Initialize the File Path: define the full path of your Parquet file
Create Input File: utilize HadoopInputFile to create an input file from the specified path
val in = org.apache.parquet.hadoop.util.HadoopInputFile.fromPath(
new org.apache.hadoop.fs.Path(fullPathUri),
spark.sessionState.newHadoopConf()
)
Open Parquet File Reader: open the Parquet file reader for the input file
val pf = org.apache.parquet.hadoop.ParquetFileReader.open(in)
Retrieve Blocks and Columns: extract the blocks from the file footer and then get the columns from the first block
val blocks = pf.getFooter.getBlocks
val columns = blocks.get(0).getColumns
Read Bloom Filter: finally, read the bloom filter from the first column
val bloomFilter = pf.readBloomFilter(columns.get(0))
bloomFilter.getBitsetSize
By following these steps, you can successfully read the bloom filter metadata from a Parquet file using the Java API in the spark-shell environment.
Discovering Parquet Version
The Parquet file format is constantly evolving, incorporating additional metadata to support emerging features. Each Parquet file embeds the version information within its metadata, reflecting the Parquet version used during its creation.
Importance of Version Awareness:
Compatibility Considerations: When working with Parquet files generated by older versions of Spark and its corresponding Parquet library, it's important to be aware that certain newer features may not be supported. For instance, column indexes, which are available in the Spark DataFrame Parquet writer from version 3.2.0, might not be present in files created with older versions.
Upgrading for Enhanced Features: Upon upgrading your Spark version, it's beneficial to also update the metadata in existing Parquet files. This update allows you to utilize the latest features introduced in newer versions of Parquet.
Checking the Parquet File Version:
The following sections will guide you on how to check the Parquet version used in your files, ensuring that you can effectively manage and upgrade your Parquet datasets. This format provides a structured and detailed approach to understanding and managing Parquet file versions, emphasizing the importance of version compatibility and the process of upgrading.
example: hadoop jar parquet-cli/target/parquet-cli-1.13.1-runtime.jar org.apache.parquet.cli.Main meta <path>/myParquetFile
Hadoop API ...
example of using Hadoop API from the spark-shell CLI
// customize with the file path and name
val fullPathUri = java.net.URI.create("<path>/myParquetFile")
// crate a Hadoop input file and opens it with ParquetFileReader
val in = org.apache.parquet.hadoop.util.HadoopInputFile.fromPath(new org.apache.hadoop.fs.Path(fullPathUri), spark.sessionState.newHadoopConf())
val pf = org.apache.parquet.hadoop.ParquetFileReader.open(in)
// Get the Parquet file version
pf.getFooter.getFileMetaData.getCreatedBy
// Info on file metadata
print(pf.getFileMetaData)
print(pf.getRowGroups)
Spark extension library The spark-extension library allows to query Parquet metadata using Apache Spark. Example:
Upgrading your Parquet files to a newer version can be achieved by copying them using a more recent version of Spark. This section covers the steps to convert your Parquet files to an updated version.
Conversion Method:
Using Recent Spark Versions: To update Parquet files, read them with a newer version of Spark and then save them again. This process effectively updates the files to the Parquet version used by that Spark release. For instance, using Spark 3.5.0 will allow you to write files in Parquet version 1.13.1.
Approach Note: This method is somewhat brute-force as there isn't a direct mechanism solely for upgrading Parquet metadata.
Practical Example: Copying and converting Parquet version by reading and re-writing, applied to the TPCDS benchmark:
bin/spark-shell --master yarn --driver-memory 4g --executor-memory 50g --executor-cores 10 --num-executors 20 --conf spark.sql.shuffle.partitions=400
val inpath="/project/spark/TPCDS/tpcds_1500_parquet_1.10.1/"
val outpath="/project/spark/TPCDS/tpcds_1500_parquet_1.13.1/"
val compression_type="snappy" // may experiment with "zstd"
// we need to do this in two separate groups: partitioned and non-partitioned tables
// copy the **partitioned tables** of the TPCDS benchmark
// compact each directory into 1 file with repartition
val tables_partition=List(("catalog_returns","cr_returned_date_sk"), ("catalog_sales","cs_sold_date_sk"), ("inventory","inv_date_sk"), ("store_returns","sr_returned_date_sk"), ("store_sales","ss_sold_date_sk"), ("web_returns","wr_returned_date_sk"), ("web_sales","ws_sold_date_sk"))
for (t <- tables_partition) {
println(s"Copying partitioned table $t")
spark.read.parquet(inpath + t._1).repartition(col(t._2)).write.partitionBy(t._2).mode("overwrite").option("compression", compression_type).parquet(outpath + t._1)
}
// copy non-partitioned tables of the TPCDS benchmark
// compact each directory into 1 file with repartition
val tables_nopartition=List("call_center","catalog_page","customer","customer_address","customer_demographics","date_dim","household_demographics","income_band","item","promotion","reason","ship_mode","store","time_dim","warehouse","web_page","web_site")
for (t <- tables_nopartition) {
println(s"Copying table $t")
spark.read.parquet(inpath + t).coalesce(1).write.mode("overwrite").option("compression", compression_type).parquet(outpath + t)
}
Conclusions
Apache Spark and Apache Parquet continue to innovate and are constantly upping their game in big data. They've rolled out cool features like column indexes and bloom filters, really pushing the envelope on speed and efficiency. It's a smart move to keep your Spark updated, especially to Spark 3.x or newer, to get the most out of these perks. Also, don’t forget to give your Parquet files a quick refresh to the latest format – the blog post has got you covered with a how-to. Staying on top of these updates is key to keeping your data game strong!
I extend my deepest gratitude to my colleagues at CERN for their invaluable guidance and support. A special acknowledgment goes out to the teams behind the CERN data analytics, monitoring, and web notebook services, as well as the dedicated members of the ATLAS database team.
Further details on the topics covered here can be found at:
 Watch sparkMeasure's getting started demo and tutorial
Watch sparkMeasure's getting started demo and tutorial